K8s单机架构部署
👨🎓博主简介
🏅CSDN博客专家
🏅云计算领域优质创作者
🏅华为云开发者社区专家博主
🏅阿里云开发者社区专家博主
💊交流社区:运维交流社区 欢迎大家的加入!
🐋 希望大家多多支持,我们一起进步!😄
🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗
这是我做了很多遍,参考很多文章得到的,为了便于大家参考和学习,我已经把每一步都整理出来了,步骤和提示都很清晰。
后续文档有什么问题那个地方写错了,大家都可以提出来。

一、 准备工作
1.1 关闭selinux及交换分区
swapoff -a //临时关闭swap
setenforce 0 //临时关闭selinux- 永久关闭swap(需要重启服务器)
vim /etc/fstab
找到带swap的哪一行,注释掉就行;之后重启服务器永久生效。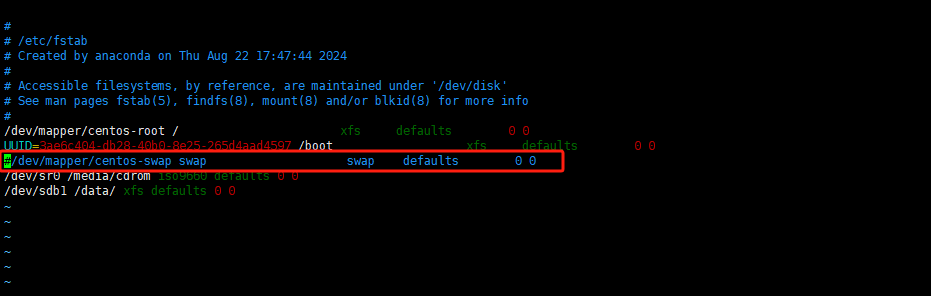
- selinux永久关闭(需要重启服务器)
vim /etc/selinux/config
将SELINUX=改为disabled
然后重启服务器即可;
每台机器的ip和uuid不能一样
cat /sys/class/dmi/id/product_uuid //每台机器的uuid不能相同
ifconfig -a //ip不能相同1.2 关闭防火墙
systemctl stop firewalld && systemctl disable firewalld如果在生产服务器之类的不能关闭防火墙,那就需要开启如下几个端口;
| 协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 6443 | Kubernetes API服务器 | 所有组件 |
| TCP | 入站 | 2379-2380 | etcd 服务器客户端API | Kube-apiserver,etcd |
| TCP | 入站 | 10250 | Kubelet API | Kubelet自身,控制平面组件 |
| TCP | 入站 | 10251 | Kube-scheduler | Kube-scheduler自身 |
| TCP | 入站 | 10252 | Kube-controller-manager | Kube-controller-manager自身 |
| TCP | 入站 | 8080 | kubelet | Kubelet自身 |
| TCP | 入站 | 30000-32767 | Node Port服务器 | 所有组件 |
1.3 允许iptables检查桥接流量(配置相关的内核参数)
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOFcat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF# 初始化
sudo sysctl --system1.4 添加centos源及扩展源
- 添加centos源并将下载地址更换为阿里云地址
#添加centos源
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
#将下载地址更换为阿里云地址
sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo- 添加epel扩展源
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo- 清除缓存
yum clean all- 重新加载源缓存
yum makecache- 升级yum并安装一些会用到的命令
yum -y update && yum -y install lrzsz wget ipvsadm ipset jq psmisc sysstat curl iptables net-tools libseccomp gcc gcc-c++ yum-utils device-mapper-persistent-data lvm2 bash-completion sshpass unzip二、部署docker
2.1 推荐安装文档及一键安装脚本
也可以自己安装docker,推荐几个安装地址或文档:
2.2 下载并解压二进制包
wget https://download.docker.com/linux/static/stable/x86_64/docker-24.0.5.tgz
tar -xf docker-24.0.5.tgz
mv docker/* /usr/bin/
# 查看docker目录下是否还有文件,没有就可以删了。
ls docker
rm -rf docker2.3 配置镜像加速
mkdir -p /etc/docker
tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://mrlmpasq.mirror.aliyuncs.com",
"https://docker.m.daocloud.io",
"https://noohub.ru",
"https://huecker.io",
"https://dockerhub.timeweb.cloud"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF众所周知,docker镜像在国内基本拉不到了,而且镜像源时不时就不能用了,不过不用担心,大家可以参考此文,每个月都会更新docker镜像源,再也不用担心docker拉镜像拉不下来了。
文章地址:https://liucy.blog.csdn.net/article/details/129085538
2.4 systemd管理docker
cat > /usr/lib/systemd/system/docker.service << EOF
[Unit]
Description=Docker Application Container Engine
After=network.target
[Service]
Type=notify
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=1048576
LimitNPROC=1048576
[Install]
WantedBy=multi-user.target
EOF2.5 启动并设置开机启动
systemctl daemon-reload
systemctl start docker
systemctl enable docker三、安装部署单机 kubernetes
3.1 添加 kubernetes 源
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
EOF- 重新加载缓存
yum makecache fast3.2 安装必要插件
kubelet和kubeadm会用到conntrack依赖;
yum -y install socat conntrack3.3 安装kubeadm、kubelet、kubectl
注:安装这几个版本不要用最新的,容易出问题,就用文章中所显示的1.20.0就行;
# 下载命令
sudo yum install -y kubeadm-1.20.0-0 kubelet-1.20.0-0 kubectl-1.20.0-0
# 设置kubelet开机自启 --now参数意思是,不仅要设置开机自启,也要立即启动该服务
sudo systemctl enable --now kubelet
# 查看是否安装成功
kubeadm version
kubectl version --client
kubelet --version
3.4 kubernetes强化tab(安装之后会tab可以补全命令及参数)
- 配置环境
echo 'source <(kubectl completion bash)' >> ~/.bashrc1、退出连接,重新连接;
2、或者bash更新环境就可以使用了。
3.5 k8s拉取镜像
先查看要拉取的镜像
[root@localhost data]# kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.20.15
k8s.gcr.io/kube-controller-manager:v1.20.15
k8s.gcr.io/kube-scheduler:v1.20.15
k8s.gcr.io/kube-proxy:v1.20.15
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns:1.7.0写成脚本,版本根据自己的要求来写
vim k8s.sh
#!/bin/bash
images=(
kube-apiserver:v1.20.15
kube-controller-manager:v1.20.15
kube-scheduler:v1.20.15
kube-proxy:v1.20.15
pause:3.2
etcd:3.4.13-0
coredns:1.7.0
)
for imageName in ${images[@]} ; do
# 拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/${imageName}
# 将镜像名称修改k8s.gcr.io/镜像
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/${imageName} k8s.gcr.io/${imageName}
# 删除原来的镜像
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/${imageName}
done# 给脚本加权限
chmod -R 777 k8s.sh
# 执行脚本,默默的等待拉取
sh k8s.sh
# 完了看镜像是否拉取成功
docker images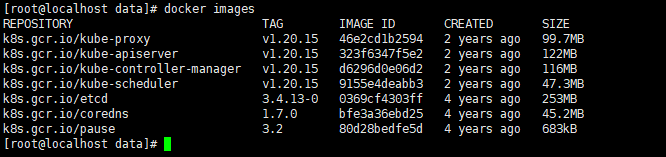
如果感觉拉取比较费劲,可以下载kubeadm所需的镜像和脚本:kubeadm所需镜像包及脚本v1.20.15版本
3.6 安装启动
如果执行kubeadm init初始化k8s失败了,在下一次执行kubeadm init初始化语句之前,可以先执行kubeadm reset命令。这个命令的作用是重置节点,大家可以把这个命令理解为:上一次kubeadm init初始化集群操作失败了,该命令清理了之前的失败环境。
172.16.11.214替换为自己的master节点IP,172.17.10.1/18替换为自己的pod网段。
1. 初始化服务(根据自己的ip和网段和版本来设置)
kubeadm init --apiserver-advertise-address=172.16.11.214 --pod-network-cidr=172.17.10.1/18 --kubernetes-version=1.20.15 |tee kubeadmin-init.log出现以下字样就是初始化成功;
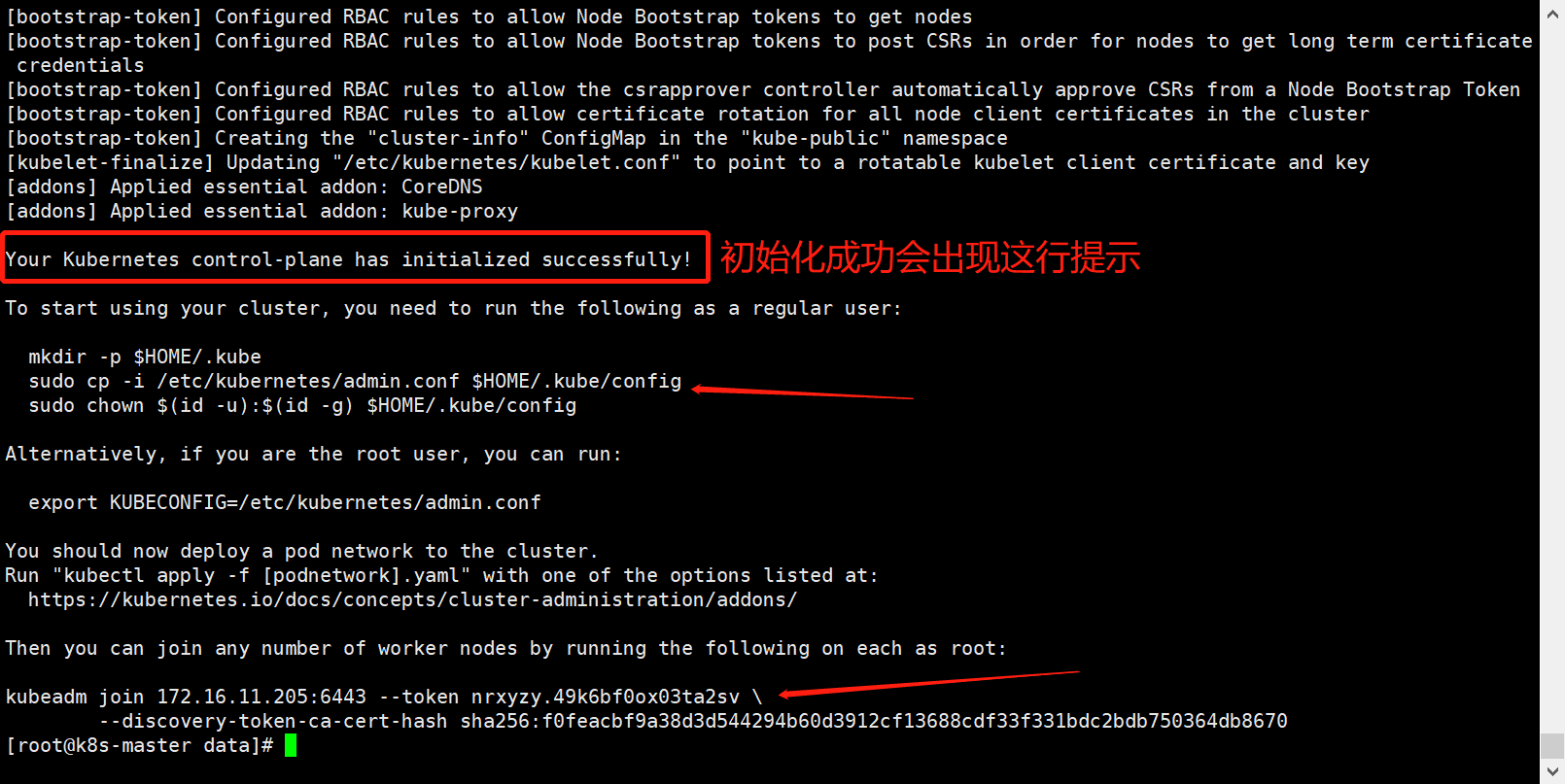
注意:
1、默认会生成证书,而证书默认有效期是一年,可使用此命令查看:ubeadm certs check-expiration,查看EXPIRES(过期日期时间)和RESIDUAL TIME(剩余时间)字段;如果查看证书RESIDUAL TIME变为负数那就是到期了,到期如何更换新的证书,可查看最后的常见问题处理中的内容;
2、生成的证书及配置在/etc/kubernetes/下,在初始化之前/etc/kubernetes/目录下是空的;
3、生成的证书位置在:/etc/kubernetes/pki下;
4、同时也会自动创建好容器,可使用docker ps -a查看;
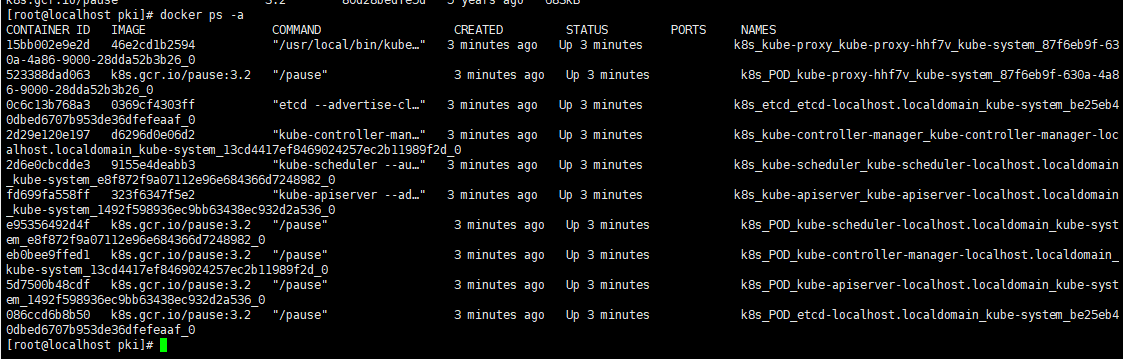
初始化完成查看一下kubelet运行状态
systemctl status kubelet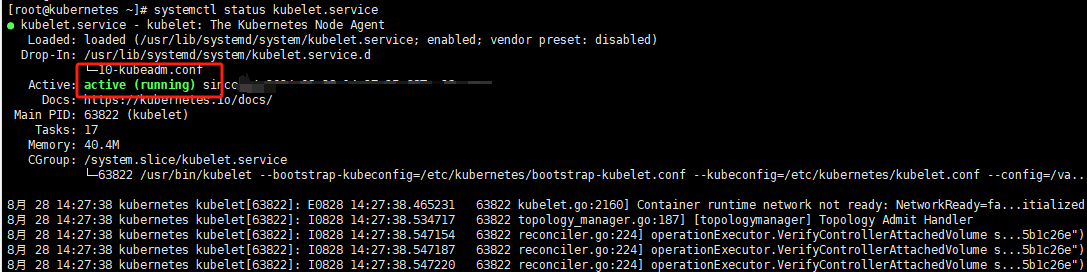
如遇初始化报错可根据
systemctl status kubelet或者journalctl -u kubelet查看报错信息来解决。
2. 注意
要使非 root 用户运行 kubectl,请执行以下命令, 它们也是在执行
kubeadm init输出的一部分:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config或者,如果你是root 用户,则可以运行:
export KUBECONFIG=/etc/kubernetes/admin.conf如果想重新初始化,可执行
kubeadm reset
也可以直接给它放到环境变量中,以免关闭服务器后重新启动出现访问不到8080端口这个问题和kubectl get nodes找不到节点问题。
vim /etc/profile
#放到最后面
# k8s nodes 配置
export KUBECONFIG=/etc/kubernetes/admin.conf
# 保存退出
# 使其配置文件立即剩下
source /etc/profile3.7 查看 nodes 节点的状态是否正常
kubectl get nodes
这时候当前节点是处于NotReady状态的;表示网络不可达;这是因为还没有安装网络插件,下面我们来安装一下网络插件(flannel)。
网络插件有:caclico和flannel,安装哪个都可以,下面是这两个网络插件的基础区别,可供参考;
- flannel:配置相对简单,易于部署和管理,特别适合小型或中型集群,或者对网络要求不高的环境。
- caclico:主要针对Kubernetes集群设计,功能强大,但配置可能相对复杂,需要更多的时间来理解和管理。
所以这里单机部署使用flannel就行;
3.8 安装 flannel(网络插件)
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
如果出现
Connecting to raw.githubusercontent.com refused,可以执行vi /etc/hosts
在后面添加 185.199.108.133 raw.githubusercontent.com;

- 添加完之后再次运行安装命令即可;
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
如果遇到下载
flannel镜像失败,可使用此链接镜像包:k8s网络插件 flannel v0.25.5 flannel-cni-plugin-v1.5.1-flannel1 镜像包
安装完之后可以使用命令验证flannel有没有成功:
kubectl get pods -ALL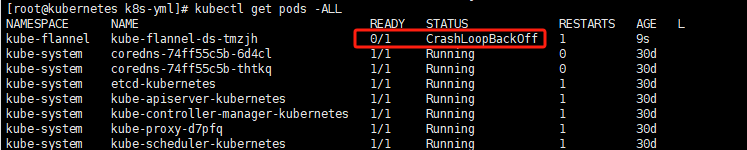
发现 kube-flannel-ds Pod 处于 状态时,这通常意味着 Flannel 网络插件无法正常启动。可以查看日志等信息进行排查;
1.检查 Flannel 日志:查看 Flannel Pod 的日志可以提供为什么它无法启动的线索。
kubectl logs -n kube-flannel kube-flannel-ds-<pod-name>查看到了报错信息如下:
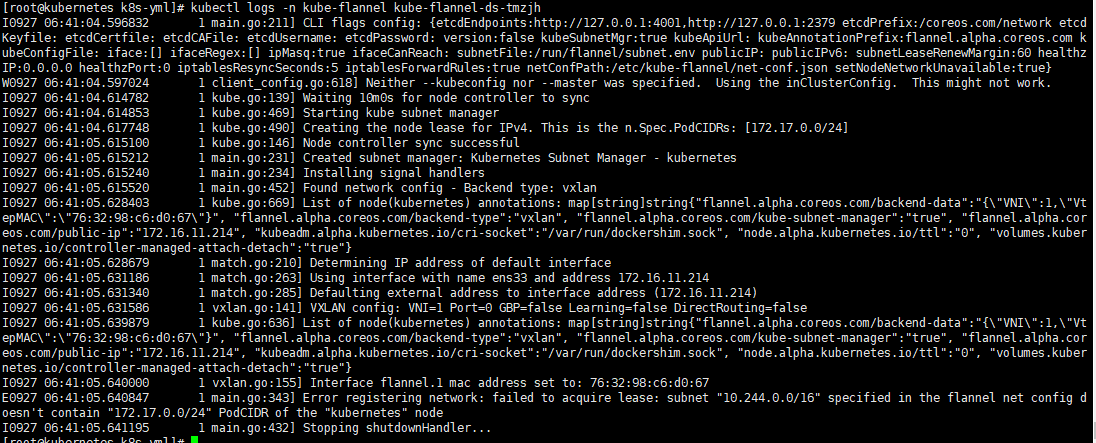
分析日志:
主要错误信息:Error registering network: failed to acquire lease: subnet "10.244.0.0/16" specified in the flannel net config doesn't contain "172.17.0.0/24" PodCIDR of the "kubernetes" node
错误信息分析:这表明 Flannel 配置的网络子网 10.244.0.0/16 不包含节点 kubernetes 的 PodCIDR 172.17.0.0/24。这是不兼容的网络配置,需要修正。意思就是和部署k8s的时候网段不兼容,需要修改一下配置和在部署k8s的时候一样就行了。
还记得我们在部署k8s时初始化服务,当时有配置ip和网段;kubeadm init --apiserver-advertise-address=172.16.11.214 --pod-network-cidr=172.17.10.1/18 --kubernetes-version=1.20.15 |tee kubeadmin-init.log
可以看到我们指定的--pod-network-cidr=172.17.10.1/18,但 Flannel 配置指定的是10.244.0.0/16,这并不匹配,我们给他换成初始化k8s时候的这个网段( kubeadm init 命令中指定的 CIDR)就可以了;
解决方法:
修改kube-flannel的configmaps配置来解决此问题;
kubectl edit configmaps -n kube-flannel kube-flannel-cfg找到网络配置这块,将他改成初始化k8s时的网段( kubeadm init 命令中指定的 CIDR)即可:
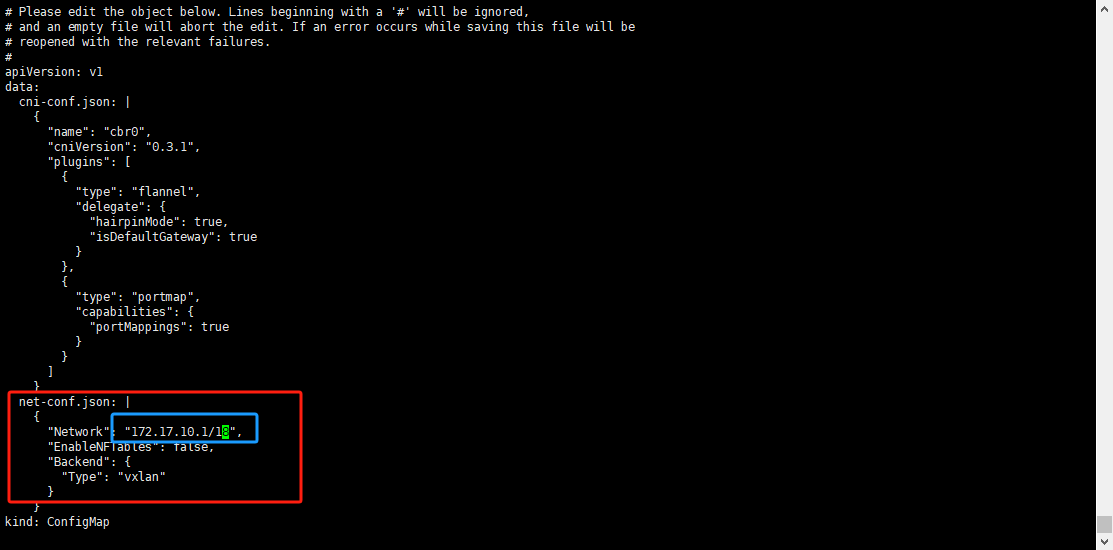
修改完之后保存退出,直接修改 ConfigMap 将自动更新 Flannel Pod,需要等待一会【大概几分钟】。
kubectl get pods -n kube-flannel
这样就可以了,就属于正常了。
在看一下全部的pod
kubectl get pods -ALL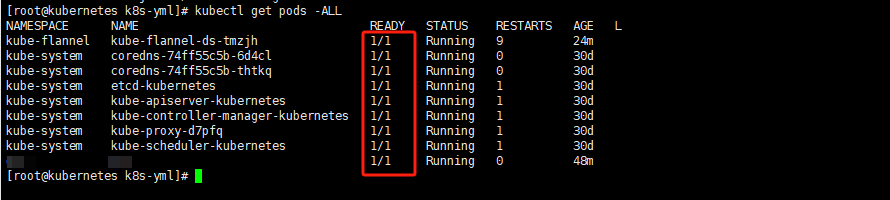
都是1/1就可以了。
3.9 验证nodes节点状态
kubectl get nodes
如果出现
Ready则代表安装完成,master节点已经注册到了k8s。
因为安装了网络插件之后他是需要自动重启连接的,所以需要等待一会,安装完网络插件之后查看如果还是NotReady状态的话,这里也可以使用此命令持续查看更新nodes节点的状态,实时观看等待连接成功;
kubectl get nodes -w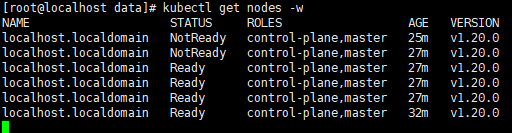
3.10 部署完成 ✔
四、常见问题处理
4.1 nodes NotReady异常处理
如果出现NotReady,可以执行以下语句判断服务器状态。
kubectl get nodes -o yaml以下绿色部分没有问题,红色部分异常message:docker: network plugin is not ready: cni
config uninitialized。
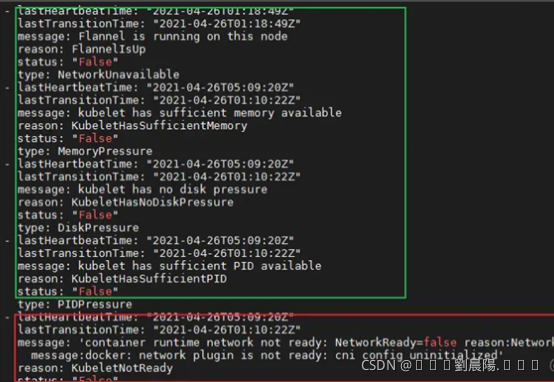
如果出现以上问题 查看日志。
journalctl -f -u kubelet.service如果出现以下日志。
"Error validating CNI config list" configList="{\n "name":
"cbr0",\n "cniVersion": "0.3.1",\n "plugins": [\n {\n
"type": "flannel",\n "delegate": {\n
"hairpinMode": true,\n "isDefaultGateway": true\n }\n
},\n {\n "type": "portmap",\n "capabilities": {\n
"portMappings": true\n }\n }\n ]\n}\n" err="[failed to find
plugin "flannel" in path [/opt/cni/bin] failed to find plugin
"portmap" in path [/opt/cni/bin]]"
执行以下命令即可
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum clean all
yum install kubernetes-cni -y4.2 重启服务器后 k8s 节点 NotReady 异常处理
重启后查看nodes节点状态,或者其他报错
[root@kubernetes ~]# kubectl get nodes
问题解决:root用户将此行写到系统环境配置里
vim /etc/profile
加到最后面
# k8s nodes配置
export KUBECONFIG=/etc/kubernetes/admin.conf再次查看如果遇到报错:The connection to the server 172.16.11.214:6443 was refused - did you specify the right host or port?
[root@kubernetes ~]# kubectl get nodes
解决:关闭交换分区,等待一会(在自启容器中)
[root@kubernetes ~]# swapoff -a
[root@localhost ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
localhost.localdomain Ready control-plane,master 21h v1.20.0或者永久关闭交换分区
- 永久关闭swap交换分区(需要重启服务器)
vim /etc/fstab
找到带swap的哪一行,注释掉就行;之后重启服务器永久生效。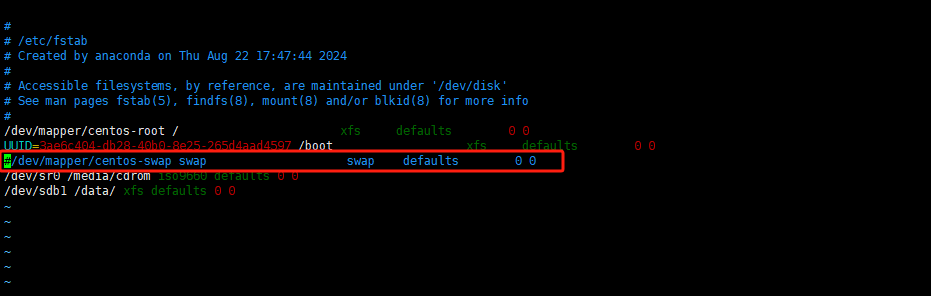
重启服务器之后查看查看node节点状态
[root@localhost ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
localhost.localdomain Ready control-plane,master 21h v1.20.04.3 查看证书RESIDUAL TIME展示为invalid,但实际证书还没到期
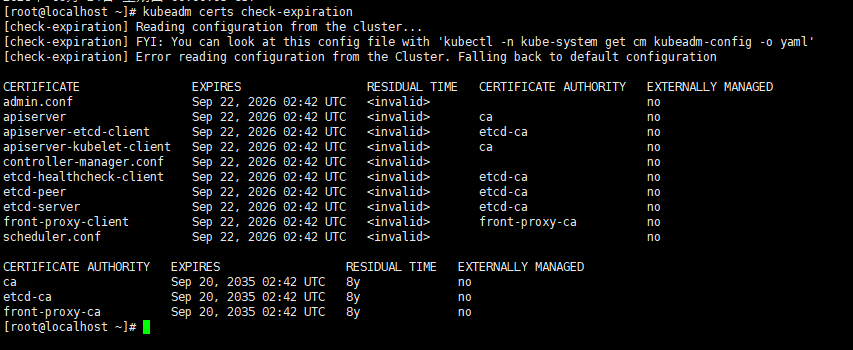
RESIDUAL TIME=invalid并不是证书过期了,而是 kubeadm 在解析本地时间时认定“当前时间”晚于证书有效期,导致它直接给出 <invalid>。
99 % 的情况是因为 系统时间不对(跳到了 2026-09-22 以后,或者时区错乱)。
把系统时间拨回正确值,再执行一次就能看到正常的剩余天数。
- 先确认是不是时间跳变
date
timedatectl如果看到年份已经跑到 2026/2027超过本年,就说明问题在这儿。
- 把宿主机时间改为正确的北京时间(任选其一)
- 手动修改时间到当日(没有网络的情况下可使用):
date -s "2025-09-22 13:09"- 通过命令同步北京时间(较为精准):
yum -y install ntpdate
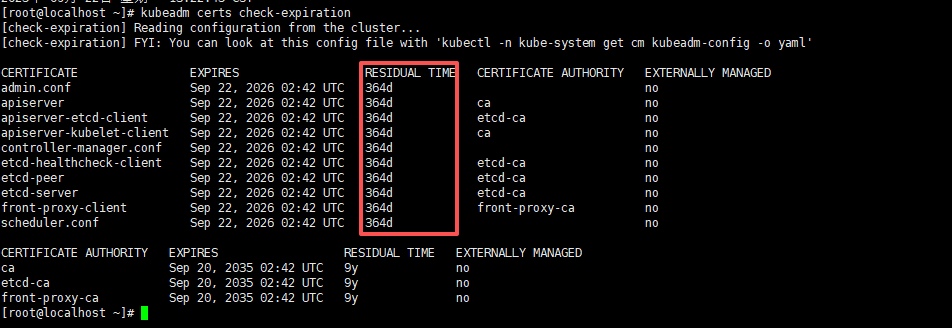
ntpdate cn.pool.ntp.org- 再检查一次
kubeadm certs check-expiration如下正常显示时间就对了;
如果日期正确后仍报 <invalid>,再考虑以下两种罕见场景:
- 证书文件本身被篡改/损坏
用 openssl 直接验:
openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text | grep "Not After"看输出是否是到期日期,例如:Not After : Sep 22 02:42:51 2026 GMT;如果不是,说明文件真坏了,只能重新生成。
- kubeadm 版本太旧(1.15 之前)对 Go 1.20+ 的时区处理有 bug
升级 kubeadm 即可。
4.4 证书到期更新
4.4.1 查看证书到期时间
可以先查看证书还有多少天到期,正常证书
小于30天的时候就可以提前更新证书了,别等 kubectl 报x509: certificate has expired or is not yet valid才更新。;
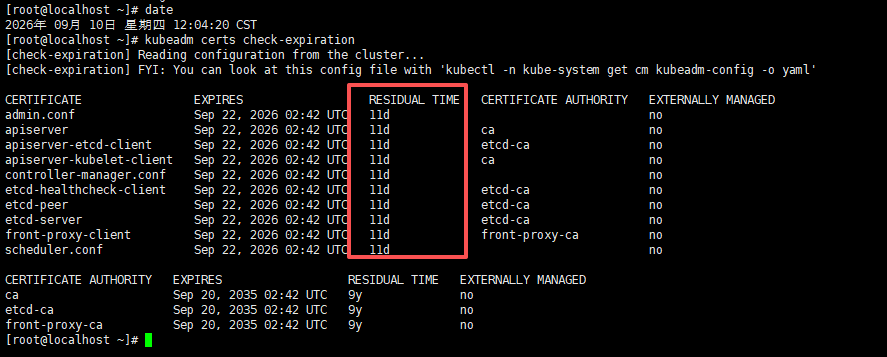
kubeadm certs check-expiration这里作为展示我就临时调整了一下日期,直接让他邻近过期时间就行;
如下还有11天就到期了,现在我们来续约证书;
4.4.2 备份旧证书及配置文件
更新前先备份,比较更新失败好回退;
sudo cp -rp /etc/kubernetes/pki /etc/kubernetes/pki-$(date +%F)
mkdir -p /etc/kubernetes/conf-$(date +%F)
sudo cp -rp /etc/kubernetes/*.conf /etc/kubernetes/conf-$(date +%F)备份完可以去/etc/kubernetes/下看一下,确保备份成功;
4.4.3 续约证书
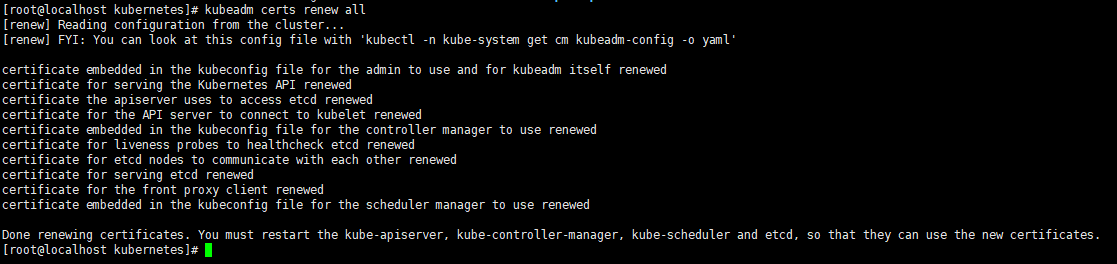
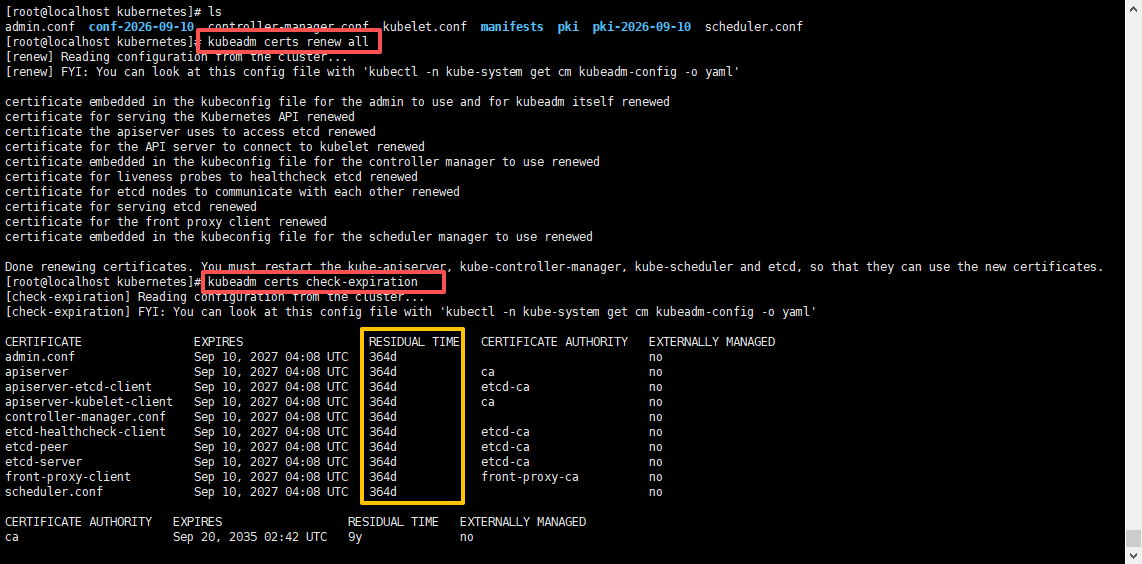
kubeadm certs renew all输出如下就是正确的;
说明
- 该命令只改证书内容,不改动私钥,也不改变颁发者,所以集群 CA 仍然有效。
- 默认再续 1 年(365d);如果想直接续 10 年可用开源脚本 https://github.com/yuyicai/update-kube-cert:
./update-kube-cert -a update --days 3650
4.4.4 重启kubelet服务
systemctl restart kubelet4.4.5 查看是否更新成功
kubeadm certs check-expiration如下证书已经更新成功了;
- 再查看
nodes节点和pods是否正常
kubectl get nodes
kubectl get pods -A | grep -E "kube-flannel|coredns|etcd|kube-apiserver|kube-proxy|kube-controller-manager|kube-scheduler"
# pods里的k8s组件需都启动:kube-flannel、coredns、etcd、kube-apiserver、kube-controller-manager、kube-proxy、kube-scheduler
nodes和pods都正常,那就说明没问题了。
如果更新好之后pod的kube-controller-manager和kube-scheduler迟迟没有正确启动可以观看下面内容。
4.4.6 更新之后kube-controller-manager和kube-scheduler未正确启动
- 首先我们通过日志来查看是为什么没用起来;
这两个都是看pod为什么没有起来的信息,可以先使用
describe查看日志,如果没有有用日志输出可以使用logs进一步查看错误信息;
# 查看 Pod 的元数据、事件、容器状态、挂载、标签、调度信息 等。
kubectl describe pod -n kube-system kube-scheduler-localhost.localdomain
# 查看 容器内主进程的标准输出/错误日志
kubectl logs -n kube-system kube-controller-manager-localhost.localdomain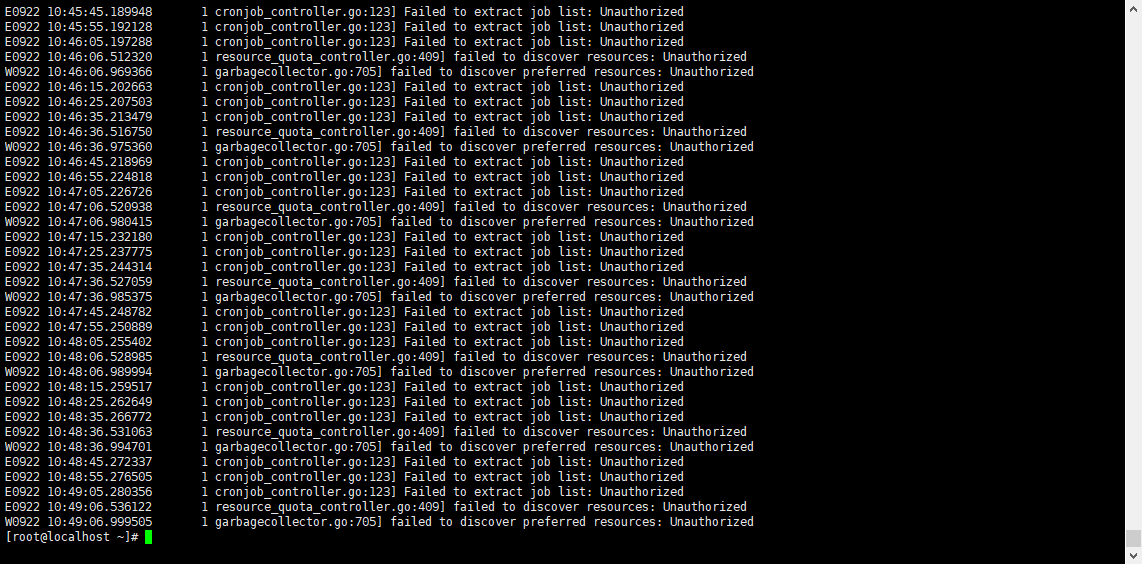
大概意思就是:证书更新后,
kube-controller-manager等组件频繁报 Unauthorized 错误,说明它们没有使用新的证书,或者没有重启导致缓存了旧证书。
所以必须要重启kubectl和control plane组件;kubeadm certs renew all只会更新证书文件内容,不会自动重启任何组件。
而 kubelet、kube-controller-manager、kube-scheduler、kube-apiserver 这些组件在启动时加载证书,之后不会自动热更新。
正确操作如下:
- 重启 kubelet
sudo systemctl restart kubelet- 重启 control plane 组件
因为我们是属于用kubeadm部署的,control plane 是以 静态 Pod 形式运行的,重启方式就是移动清单文件,先给他移动出去,在移动回来,从而让其他组件重新启动:
# 先备份manifests 目录
sudo mv /etc/kubernetes/manifests /etc/kubernetes/manifests.bak
# 然后看docker容器(针对于本篇文章部署的),等apiserver、controller-manager、scheduler这几个容器没了,就可以把备份的目录还原回去了;
# 可以使用命令持续监控docker的容器状态
watch 'docker ps | grep -E "apiserver|controller-manager|scheduler"'
# 预估等个1-5分钟左右基本都会删除,遇到慢点的可能需要10分钟左右,如果持续监控都空了之后就可以还原回去了;
sudo mv /etc/kubernetes/manifests.bak /etc/kubernetes/manifests
# 还原回去之后再等半分钟左右,再次检查日志;- 重启完之后再次检查
kube-controller-manager日志;
kubectl describe pod -n kube-system kube-controller-manager-localhost.localdomain
kubectl logs -n kube-system kube-controller-manager-localhost.localdomain发现还是有报错,但这次的报错和上次的不一样了;
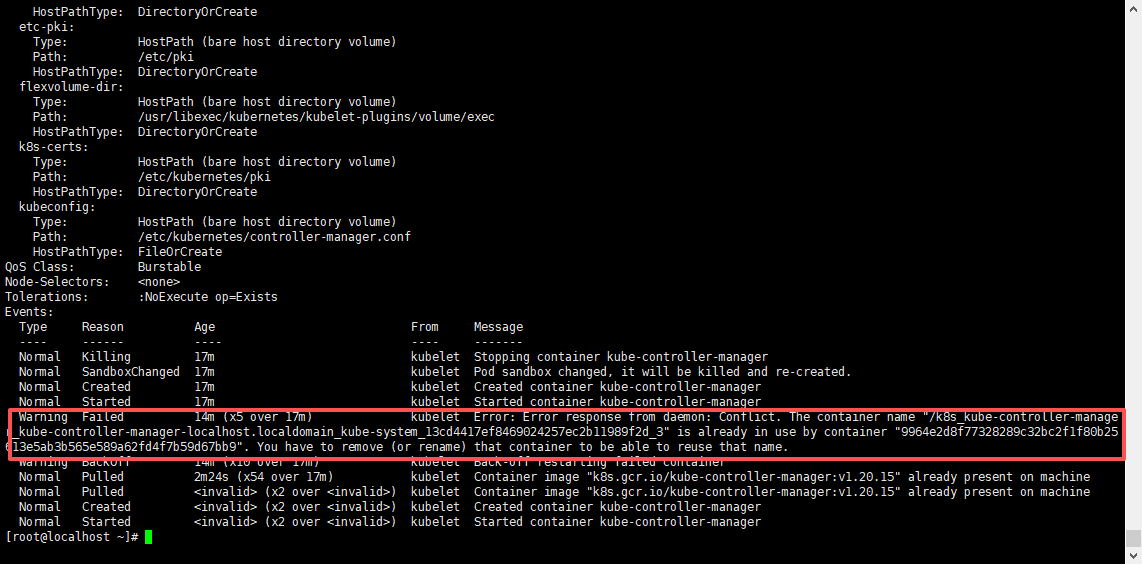
错误翻译是:kubelet错误:kubelet错误:来自守护进程的错误响应:冲突。容器名称“/k8s_kube-controller-manager _ kube-controller manager-rhost.localdomain_cube-system_13cd4417ef8469024257ec2b11989f2d_3”已被容器“9964e2d8f77328289c32bc2f1f80b25613e5ab3b565e589a62fd4f7b59d67bb9”使用。您必须删除(或重命名)该容器才能重用该名称。
这个报错的意思总结就是:新的k8s_kube-controller-manager起不来,因为旧的容器没有删除掉,名字被占用了,所以必须要把旧的k8s_kube-controller-manager容器删掉或者重命名就可以了;
# 查看所有的k8s_kube-controller-manager容器
docker ps -a | grep k8s_kube-controller-manager
会发现有两个
k8s_kube-controller-manager的容器一个是启动的状态,一个是退出的状态,那么该删除哪个呢?
报错说是新创建的被9964e2d8f773容器给占用了,但不能删除正在运行的这个容器,为什么呢?
因为删除正在运行的之后,会把活的进程干掉,kubelet 被迫再建,循环报错,所以不能删除正在运行的这个容器,可以吧退出状态的容器删除掉就可以了。
删除之后在执行docker ps -a | grep k8s_kube-controller-manager就不会新增了k8s_kube-controller-manager容器了;
# 容器id替换成自己的
docker rm -f 8ef5afeefa16- 再次检查
kube-controller-manager状态
可能需要等待1-3分钟左右就会恢复正常,可使用如下命令持续监控kube-controller-manager的pod的状态;
kubectl get pods -n kube-system kube-controller-manager-localhost.localdomain -w
就可以发现已经变正常了;
- 接下来再看看
kube-scheduler为什么也没起来
同样的方法,先使用describe查看日志,如果没有详细输出在使用logs查看pod的输出信息;
kubectl describe pod -n kube-system kube-scheduler-localhost.localdomain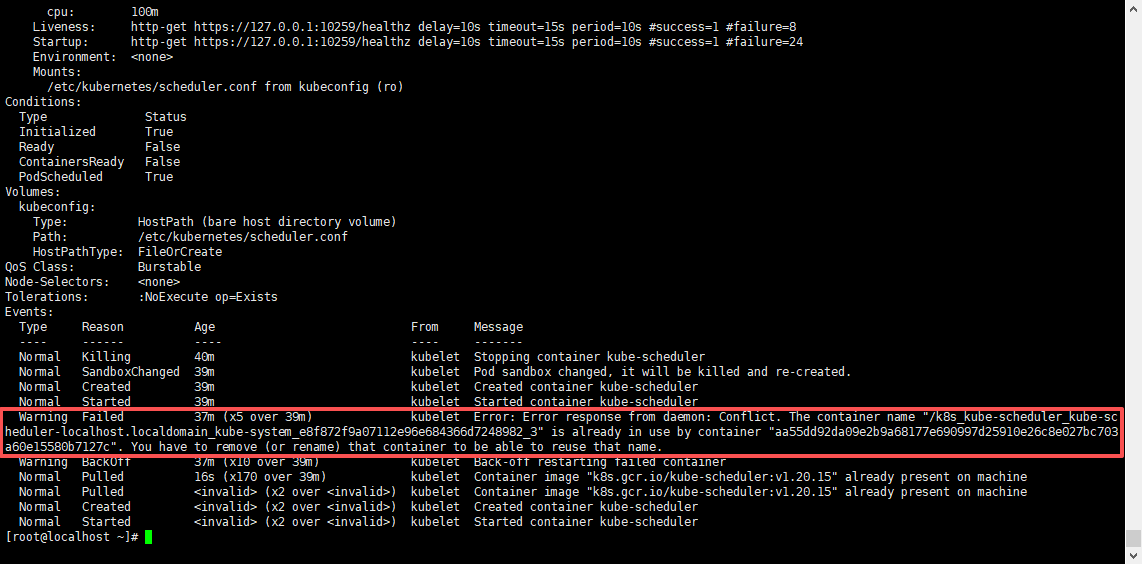
这里其实和kube-controller-manager的报错是一样的,容器名称被占用了起不来,按照上面的方法吧退出的kube-scheduler删掉就可以了;
# 查看k8s_kube-scheduler容器,吧退出状态的删除就可以了;
docker ps -a | grep k8s_kube-scheduler
# 容器id替换成自己的
docker rm -f 381fe8033c78删除之后再次查看kube-schedulerpod的状态,需要等待1-3分钟左右就会恢复正常,可使用如下命令持续监控kube-scheduler的pod的状态;
kubectl get pods -n kube-system kube-scheduler-localhost.localdomain -w
就可以发现已经变正常了;
- 最后再把所有的所需组件检查一下
kubectl get pods -A | grep -E "kube-flannel|coredns|etcd|kube-apiserver|kube-proxy|kube-controller-manager|kube-scheduler"
状态都是1/1就没问题了,至此证书更新就可以结束了。